 Table of Contents
Table of Contents
 Previous Chapter
Previous Chapter
ACIS
The purpose of the IPCL Code-Generator is to interpret the command and telemetry structure definitions provided in the "ACIS Instrument Program and Command List" (MIT3601410) database and produce C++ source code to read fields from command and parameter block buffers, and to format data into telemetry packet buffers.
- Write C++ classes which read fields from command packet buffers
- Write C++ classes which write fields into telemetry packet buffers
The IPCL Code-Generator is written entirely in Perl and is contained in within three files: ipcl_gen.pl, ipcl_reader.pl, and ipcl_writer.pl. The code-generator reads in the IP&CL structures definition from a file containing lists of tab-separated values, with newlines separating entries in the database. The format of the IP&CL structures is described in Section 21.4 . The output of the code-generator is a set of C++ header and source files, one for each structure being read or written. Templates for the generated C++ files are described in Section 22.0 and Section 23.0 .
Figure 83 illustrates the main inputs and outputs of the IP&CL code-generator.
FIGURE 83. IPCL Generator Context Diagram
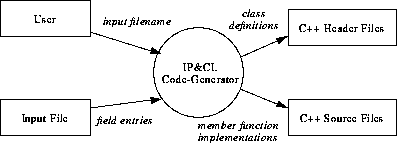
The user invokes the Perl IP&CL Code-Generator script passing it the name of the IP&CL Structures table file, input filename. The code generator opens and reads all of the field entries from the Input File. It then parses the field entries, and produces a series of C++ header and source files, one for each record structure defined in the input file. Each record structure is represented by a C++ class. The header files will contain the class definitions for the defined classes, and the source files contain the member function implementations for these classes.
Figure 84 illustrates the Level-1 data flow of the IP&CL code-generator.
FIGURE 84. IPCL Generator Level-1 Data Flow Diagram
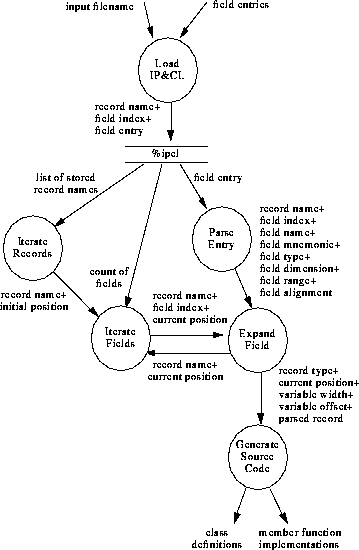
The following describes each data element illustrated in Figure 83 and Figure 84:
input filename - This identifies the file which contains the IP&CL Structure records to process.
field entries - These are the field definitions read from the IP&CL input file. Each entry contains a list of tab-separated ASCII elements, and ends with a newline character. See Section Section 21.4.2 for a description of the format of a field entry.
class definitions - These are the definitions for each generated C++ class.
member function implementations - These are the implementations for each member function of a class.
record name - This is the ASCII name of a record as defined in the IP&CL database. All fields belong to one record or another, and each field entry contains the name of the record to which it belongs. The code-generator uses the record name as part of a database key when indexing field entries. The code-generator includes a modified form of the record name when generating class names, and C++ header and source code filenames.
field index - Each field within a record is numbered. The code-generator uses the field index in its database key when indexing field entries.
%ipcl - This is a Perl associative array of IP&CL field entry counts and field entries. Array elements keyed using a record name alone return the number of fields defined for the named record. Elements which are keyed using a record name and field index, separated by the value of the Perl variable, $;, contain the field entry string, as read from the IP&CL input file.
$ipcl{record name} = count of fields for the named record
$ipcl{record name, field index} = field entry string
list of stored record names - This list is generated by asking Perl to produce an array of all database keys, and then sorts the list and prunes out any key containing the value of the $; Perl variable.
initial position - This item represents the initial bit-position of the current record being produced. This item's value is always 0.
count of fields - This represents the number of fields defined for a given record. It's value for a given record is contained in $ipcl{record name}.
current position - This item represents the current bit-position within a given record definition. It is used to compute the bit-position of a field or record, and to determine the need for padding if a field has a bit alignment requirement.
field name - This is the name of a field defined in the IP&CL database. The code-generator includes a modified form of the field name when generating member function names. NOTE KLUDGE: On occasion, the generator also uses this name to identify fields which are intended to be grouped into an array. A set of two or more adjacent fields, which have the same base name, and whose names end with incrementing numbers starting from 0, may be treated as elements of an array by the code-generator.
field mnemonic - This is an 8-character mnemonic for the field in the IP&CL.NOTE KLUDGE: The code-generator uses the mnemonic of the first field of a record to determine whether the record defines a command packet structure, a telemetry packet structure or is an internal structure. If the last two characters of the mnemonic are "CI," then the code generator treats the record as a command packet. If the last two characters are "XF," then it treats the record as a telemetry packet. All others are treated as internal structures, and are ignored by the code-generator.
field type - This identifies the data type of the field. For ACIS software structures, a field has one of the following types:
int8 - signed, 8-bit integer
uint8 - unsigned, 8-bit integer
int16 - signed, 16-bit integer
uint16 - unsigned, 16-bit integer
int32 - signed, 32-bit integer
uint32 - unsigned, 32-bit integer
bit - bit-field where field dimension determines the number of bits
in the field.
record name - The name of another record definition. The data type
of the field is defined by the referenced record.
field dimension - This specifies the number of elements of field type in the field. If the field dimension is not 1, then the field represents an array of elements. If the field dimension is a constant expression, then the array is of fixed length. If the value of the dimension relies the value of another field within the record, then the field has a variable number of elements. Fields representing variable length arrays must always appear at the end of the record definitions. No other fields may appear after the variable array within the record. field dimension may be expressed as formula. The formula parsing rules are as follows:
DECIMAL = [0-9]+
OCTAL = 0[0-7]*
HEXADECIMAL = 0x[0-9, a-f, A-F]+
NUMBER = DECIMAL | OCTAL | HEXADECIMAL
VARIABLE = field name
OPERATOR= `*'|`DIV'|`+'|`-'|`bitoffset'|`bitsize(record name)'
TERM = NUMBER | VARIABLE | TERM OPERATOR TERM | `(' TERM `)'
For example, a common dimension formula for a command packet field is:
((command length * 16) - bitoffset) DIV bitsize(field type)
field range - This specifies the lowest and highest acceptable value for the field, and is used by the code-generator when producing sanity checks of input arguments or read field values.
field alignment - This specifies the bit-alignment requirement of the field. The code-generator may add pad bits between the previous field and the current field to satisfy the alignment requirement.
variable width - This is the computed number of bits within one element of a variable length array. This width includes any pad bits needed to satisfy alignment requirements of the array elements.
variable offset - This is computed bit offset of the start of a variable length array.
parsed records - This represents the parsed record structure used by the code-generators to produce C++ class definitions and implementations. It consists of an array of keywords and values and has the following form:
parsed records = RECORD
TERM = RECORD | FIXED | VARIABLE | FIELD
RECORD = `record' recordname curoffset TERM* `endrecord'
FIXED = `fixed' fieldname curoffset width dimension TERM* `endfixed'
VARIABLE = `variable' fieldname curoffset width dimension TERM* `endvariable'
FIELD = `field' fieldname curoffset width sign srange erange `endfield'
where curoffset is the bit-position of the element, width is the number of
bits within the field or 1 element of a fixed or variable length array, dimen
sion is the formula for the number of elements in the array, sign is 0 if the
field is unsigned and 1 of the field is signed, srange is the lowest value
that the field supports, and erange is the largest value the field supports.
NOTE: The IP&CL structures definitions table format is still being design Final definition of the fields is TBD.
The code-generator reads the IP&CL information from an ASCII file. The file contains one line per record field entry, each ending in a newline character. Each entry contains the same number of elements, each separated by a tab character.
Each field entry consists of the following elements, in the listed order:
 TABLE 23. IP&CL Field Entry Format
TABLE 23. IP&CL Field Entry Format
------------------------------------------------------------------------------------------------------
Element Description
------------------------------------------------------------------------------------------------------
Record Text This describes the record defining the field
Record Name This is the name of the record defining the field
Field Number This is the field position within the record
Subfield Number This is the subfield position within the record
Owner This identifies the owner of the record. For ACIS it is always `ACIS'
Field Name This is the name of the field
Mnemonic This is the field's 8-character mnemonic. For ACIS software, the mne
monic has the following structure: 1rrffAss, where `1' identifies the mne
monic as an ACIS field, `rr' is the record number in hexadecimal, `ff' is
the field number in hexadecimal, `A' specifies the port side, and `ss' is
used to identify the type of record being defined. If `ss' is CI, the record is
a command packet definition. If it is `XF', it is a telemetry packet, and if
it is `IT', it is an interal record.
Data Type This specifies the data type of the field. This may have the following val
ues: int8, uint8, int16, uint16, int32, uint32, bit, or the name of a record.
Dimension If the field defines an array, this specifies the number of elements in the
array. The dimension statement may consist of a formula, which may
refer to fields within the record, may contain parenthesized expressions,
and which uses the following operators and keywords: +, -, *, DIV, bitoff
set, bitsize(`record name')
Maximum Dimension This specifies the maximum number of elements that can be held by the
field.
Variable Record Flag This indicates whether the fields in the record have constant or variable
values
Field Description This describes the field
Byte Size This is the number of bytes in 1 element of the field. Its value is computed
by TRW.
Total Size This is the total number of bytes being defined by the field. Its value is
computed by TRW.
Start Range This is the minimum value the field can have.
End Range This is the maximum value the field can have.
Units This specifies the units of the field
Value If the field has constant value, this specifies the value.
Format This identifies the printing format to use for the field
Question This entry is TBD.
Alignment This specifies the bit-alignment requirements of the field.
Command Time-out This specifies the command time-out period, if the field is part of a com
mand packet record definition.
------------------------------------------------------------------------------------------------------
This section illustrates the structure of the main portion of the code-generator script, ipcl_gen.pl. The unshaded functions are contained within ipcl_gen.pl and the shaded functions are provided by either ipcl_reader.pl or ipcl_writer.pl.
FIGURE 85. ipcl_gen.pl Structure
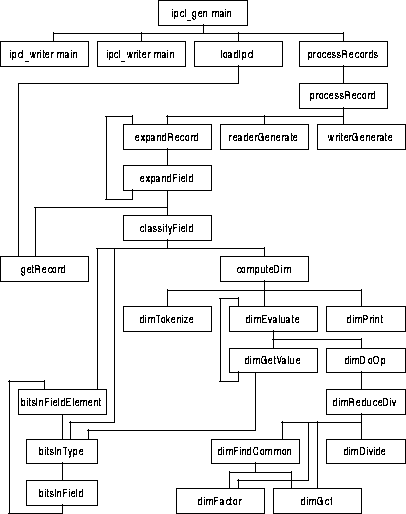
- ipcl_gen main - This is the main function of ipcl_gen.pl. It includes and executes ipcl_writer.pl and ipcl_reader.pl, calls loadIpcl() to load the IP&CL field entries, and calls processRecords() to process the loaded entries.
- ipcl_writer main - This is the main set of commands executed when ipcl_writer.pl is included or invoked. These commands are described more detail below.
ipcl_reader main - This is the main set of commands executed when ipcl_reader.pl is included or invoked. This commands are described more detail below.
- loadIpcl - This subroutine takes the IP&CL filename as input, opens the file and reads the field entries from the file, parses the entries, using getRecord(), to obtain the record name and field index contained in the entry, and stores the field entries into the associative array %ipcl. Upon returning, $ipcl{record name} contains the number of fields defined by a particular record, and $ipcl{record name, field index} contains the a copy of the field entry.
- getRecord - This function takes one field entry string, consisting of a series of tab-separated elements, and returns an associative array containing each element. The keys used for the array are:
rtext - Description of the record
rname - Record name
fnum - Field index
subf - Subfield index
owner - Record owner, always `ACIS'
fname - Field name
mnem - Field mnemonic
type - Field type
dim - Field dimension
maxdim - Maximum dimension
var - Variable record
ftext - Field description
sizeb - Size of field in bytes
tsize - Total size of field in bytes
srange - Lowest value contained in field
erange - Highest value contained in field
units - Units of value contained in field
value - Fixed value of field
fmt - Printing format for field
quest - Questions???
align - Bit-alignment requirements of field
cmdto - Command Timeout requirements for command records
- processRecords -This function is responsible for generating C++ classes for all command and telemetry records in the loaded IP&CL. This function iterates through each record definition in %ipcl, calling processRecord() for each.
- processRecord - This function is responsible for generating C++ code for a single record. This function takes a record name as input, and generates C++ code for the passed record. It calls expandRecord(), passing the record name and an initial bit-position of 0, and getting back the record type, some variable length information, and the parsed record. It then uses the record type to determine if it is generating command packet reader classes, or telemetry packet writer classes, calling readerGenerate() or writerGenerate(), respectively.
- expandRecord - This subroutine takes a record name and current position as inputs and produces a parsed record array, of the form:
RECORD = `record' recordname curoffset TERM* `endrecord'
- It starts by placing the `record' keyword followed by the record name and current position at the start of its output array. It then gets the number of fields defined by the record from $ipcl{record name}, and iterates through each field, calling expandField() for each field it processes. If the field is the first in the record, it sets the expanded field type as the current record type. If the expanded field contained a variable length array, it uses the field's element width and bit-position as the record's variable element width and array bit-position. It then concatenates the parsed record array returned by expandField() to the end of its parsed record array. Once all of the fields have been processed, the function appends an `endrecord' keyword to the parsed record array, and returns the record type, the new current position, the variable width, variable offset, and the generated parsed records array.
- readerGenerate - This function is provided by the script, ipcl_reader.pl. For input, it takes an optional parent class name, an optional basename to use for the generated classes, an optional record name of the packet header to prevent it from generating unnecessary access functions to the header (they're already inherited by parent's functions), an inline member function flag, indicating whether or not to generate inline member functions, and a parsed record array. readerGenerate creates and emits a C++ class definition and member function implementations for the record defined in the parsed records array. The class provides member functions which read bit-fields from within a command packet buffer.
- writerGenerate - This function is provided by the script, ipcl_writer.pl. For input, it takes an optional parent class name, an optional basename to use for the generated classes, an optional record name of the packet header to prevent it from generating unnecessary access functions to the header (they're already inherited by parent's functions), an optional variable width, an optional variable offset, a inline member function flag, indicating whether or not to generate inline member functions, and a parsed record array. readerGenerate creates and emits a C++ class definition and member function implementations for the record defined in the parsed records array. The generated class provides member functions which write bit-fields into a telemetry packet buffer.
- expandField - This function is responsible for processing a single field within a record. It takes the record name, the field index, and the current position as input. It retrieves the field entry from $ipcl{record name, field index}, and passes the entry string to getRecord() to produce an associative array of the field entries. It then determines the field type by examining the field's mnemonic. If the last two characters of the mnemonic are `CI', then it sets its local record type to a command packet. If the last two characters are `XF', it sets record type to a telemetry packet, otherwise, it assumes the record type is internal. It then check's the field's alignment requirements, and adds any needed padding to the current position. It then passes the record name, the field index, the current offset and the associative array of field elements to classifyField() to compute and determine various properties of the field. classifyField() returns and associative array of field properties, %props. The function then proceeds to produce append information to the parsed records array. If the field defines a fixed length array ($props{isfixedarray}), the function appends the keyword `fixed', followed by the field name, the current offset, the width of one element in the array ($props{arraywidth}), and the dimension of the array ($props{limit}) to the end of the parsed records array:
FIXED = `fixed' fieldname curoffset width dimension TERM* `endfixed'
- Otherwise, if the field is a variable length array ($props{isvararray}) the function sets the variable width to return to the element's width ($props{arraywidth}, and the variable offset to the current position. It then appends the keyword `variable', followed by the field name, the current offset, the width of one element in the array ($props{arraywidth}), and the dimension formula for the array ($props{limit}) to the end of the parsed records array:
VARIABLE = `variable' fieldname curoffset width dimension TERM* `endvariable'
- If the field has a simple data type ($props{basetype}), the function appends the keyword `field', followed by the field name, the current offset, the width in bits, the sign, the field's range, and the keyword `endfield' to the parsed records array and advances the current offset by the bit-width of the field ($props{bitwidth}):
FIELD = `field' fieldname curoffset width sign srange erange `endfield'
- Otherwise, the field has a complex data type and the function recurses and passes the field type and current offset to expandRecord() to expand the type into a parsed record array, which is then concatenated to its local array. If the processed record ends with a variable length array, the function logs the record's variable width and offset.
- If the processed field was a fixed length or variable length array, the function respectively appends the `endfixed' or `endvariable' keyword to the parsed records array.
- It then returns with the record type, the modified current offset, the variable width, variable offset, and the modified parsed record array.
- classifyField - This function determines various properties of a particular field. For input, it takes the record name, the field index, the current position, and the associative array of field elements. On output, it returns an associative array, where the keys are as follows:
basetype - Indicates if field type refers to an integer or bit-field
isvararray- Indicates if field defines a variable length array
isfixedarray - Indicates if field defines a fixed length array
bitwidth - For integer/bit types, contains the bit-width of the field
limit - For arrays, defines the number of elements in the array
sign - For integer types, indicates if field is unsigned or signed
srange - For integer/bit types, indicates lowest value of field
erange - For integer/bit types, indicates largest value of field
arraywidth - For arrays, contains bit-width of 1 element in the array
- The function starts by passing the field's dimension expression, current offset, and alignment requirements to computeDim() to reduce the dimension expression to its simplest form, and assigns the result to $props{limit}. If the expression is not 1, then the field defines an array, and the function checks to see if the expression represents a single number, or represents a formula. If the former, then the array is fixed length, and the function sets $props{isfixedarray}. If the expression is not a simple number, then the field represents a variable length array, and the function sets $props{isvararray}.
- It then checks the field type against the base integer and bit type keywords. If the type matches, the function sets $props{basetype}, and calls bitsInType() to extract the number of bits in the field and copying the result to $props{bitwidth}. If the field's type is a bit-field, and has a dimension less than or equal to 32, it converts the fixed length array of bits into a single element by setting $props{bitwidth} to $props{limit}, and setting the $props{limit} to 1. The function then determines the sign of the field, and sets $props{sign} to 0 if the field is unsigned, and to 1 if it is signed. It then assigns the start and end range properties of the field based on the passed entry's value, srange, and erange components.
- Finally, if the field is a fixed length or variable length array, the function calls bitsInFieldElement() to compute the size of a single element in the array, and adjusts the result by any alignment requirements of the field. The result is stored in $props{arraywidth}.
- The function then returns the constructed associative array of properties.
- bitsInType - This function computes the number of bits within a data type. The inputs to the function are the type name, and the current offset. If the type is a bit, it returns 1 for the width. If it is a simple integer type, it returns the appropriate number of bits for that type. If the type is a record name, it iterates through each field in the record, passing the record name, field index, and current position to bitsInField() for each field in the record, and adds the returned bit-size to the current total for the record and to the current position. Once all fields have been processed, it returns the computed total.
- bitsInFieldElement - This function computes the number of bits within 1 array element of a field, or if the field is not within an array, then of the field itself. The inputs to the function are the field entry to be processed, and the current position. It returns the computed size of the field element. The function passes the field entry string to getRecord() to get an associative array of the entries elements. It then determines if any padding is needed to maintain the alignment of the field, based on the current position and the alignment requirements of the field. If so, it adds the needed padding to the total size of the field element and the current position. The function then calls bitsInType() to compute the size of 1 element of the field, and returns the padded size.
- bitsInField - This function computes the total number of bits within all elements of a field. This function cannot be used on a field which defines or contains variable length array. The inputs to the function are the field entry string and the current position. The function calls getRecord() to obtain an associative array of the field entry elements. It then calls bitsInFieldElement() to determine the size of a single element in the field (if the field is an array). It then multiplies the returned size with the dimension of the field and returns the result.
- computeDim - This function interprets and reduces a field's dimension expression to its simplest form. Its input arguments are the field's dimension expression string, the current position of the field, and the field alignment requirement. The function returns a reduced form of the expression. The function starts by checking if the dimension is already a simple number. If it is, the function just returns the dimension string. If not, it passes the dimension string to dimTokenize(), which splits the string into tokens and returns the array of tokens. The function then passes the current position, the field's alignment requirement and the token array to dimEvaluate(), which interprets and simplifies the expression. dimEvaluate() returns an array of token strings. From the top level, the array consists of 1 item, which is a tab-separated of expression elements. The function splits this string into an array, clears the variable $dimStrOut, and calls dimPrint() to reformat the tokens into an expression string, storing the result into $dimStrOut. The function then returns the formed string.
- dimTokenize - This function parses a field's dimension string into an array of tokens. The input to the function is a field's dimension string, and it returns an array of tokens. The function first builds a regular expression string which consist of an "or" pattern of expressions, where each matches a particular token. It then splits the dimension string into an array using the regular expression. It then enters a loop which re-constructs any multiple word symbol tokens back into a single token string. It then returns the token array.
- dimEvaluate - This function reduces a list of dimension tokens into a simplified set of dimension expression tokens. The input to the function is the current position, the alignment requirement of the field, and an array of dimension statement tokens. The routine returns a reduced set of tokens. This routine recurses, and once it returns to the top level, the array of tokens will contain 1 element, a string of tab-separated dimension expression statements. The string contains the simplified formula, consisting of tab-separated operators and values in Reverse-Polish-Notation (RPN). Variables names within the array are surrounded by `#'s. This eases searching and replacing the variable names with source-code names. For example, the formula:
((length * 16) - 11) / 9
- is expressed as (parenthesis are shown only for readability):
/ - * #length# 16 11 9
- A single symbol or value, with no operators, means that the dimension expression reduced to a single value. An expression starting with the operators `*', `/', `+', `-' are followed by a left and right side expression.
- dimGetValue - This function process the next value token from the array of dimension expression tokens. The input to the function is the current position, the field alignment requirements, and the current token array. The function returns the token array, with the resolved argument. If the first token is an open parenthesis, the function recursively calls dimEvaluate() to resolve the expression contained within the parenthesis, replacing the expression tokens with the resolved expression. If the first token is a minus sign, the function forms a binary expression by inserting 0 to the beginning of the token array. If the first token is a hexadecimal number, the function replaces the token with the decimal equivalent. If the first token is the `bitoffset' keyword, the function replaces the keyword with the passed current position. If the first token is the `bitsize(record name)' expression, the function calls bitsInType() to compute the number of bits in the specified record, adjusts the result by the passed field alignment requirement, and replaces the expression with the computed size. If the operator is a symbol, the function places `#' characters on either side of the symbol allow code-generation to locate and replace the symbol within an expression string.
- dimDoOp - This function attempts to evaluate an expression. The inputs to the function are the left side of the expression, the operator to use, the right side of the expression, and the current array of dimension tokens. On output, the result is inserted into the beginning of the token array and the array is returned to its caller. The function first checks the left and right side expressions. If either is not a simple numeric value, the function forms an RPN expression of the form `operator left right', using dimReduceDiv() to reduce division expressions if the operator is `DIV' and the right argument is a number. If both sides of the expression are numbers, the function evaluates the expression.
- dimReduceDiv - This function attempts to reduce a division expression to a simpler form. The function takes the denominator value, followed by the array of dimension tokens containing the numerator as input. On output, the function returns an array of tokens containing the reduced expression. The function calls dimFindCommon() to find some common factors between all terms in the numerator. It then calls dimFactor() to partially factor the denominator value. It then calls dimGcf() to find the common components between the terms in the numerator and in the denominator. The function then multiplies the common components to form a common factor, and divides each term in the numerator by this factor. The result is inserted into the token array. It then checks the denominator. If the denominator and the factor are not the same value, the function inserts the `/' operator into the array, and appends the result of `den / factor' to the end of the array.
- dimFactor - This function returns a string containing a list of factors of a particular number. The function takes the number to factor for input, and returns a string of $; separated factors of the value. The factoring may be incomplete, and the last value in the list contains the un-factored remainder. The product of all elements in the list result in the input value. If the input value is 0, the function returns `1'. If not, it attempts to factor the number. It forms a small list of prime numbers, and iterates through the list. While the current value is evenly divisible by a given prime, the function adds the prime to the output list and divides the value by the prime. Once the value reaches `1' or the list of primes is exhausted, the function sorts the resulting list into descending order, forms the output string from the list and returns the string.
- dimFindCommon - This function finds common factors in an expression's terms. The function takes an array of expression tokens on input, outputs a list of factors in the $dimFactors string, and returns the surviving expression tokens to its caller. The function removes the first value from the token array. If it is a `+' or `-', the function finds the common factors between the left and right sides of the expression. If it is a `*', it factors both sides of the expression and combines the two into a single list. If the value is a number, it factors the number.
- dimGcf - This function compares two lists of factors, and produces a list of those in common between the two lists. The input is two strings, containing factor values delimited by $;. On output, the function returns a string containing the common values delimited by $;. The function clears its output array, splits the second input string into an array, and retrieves the first value from the array. It splits the first string into an array and iterates through the array. For each element in the first array, the function searches the second array until it finds a value less than or equal to the value from the first. If the values are equal, the function adds the value to the output list, and advances both lists. Once all values have been check, the function joins the output array into a single string and returns it to its caller.
- dimDivide - This function divides a compound expression by a single value. On input, the function takes the denominator value to use, and an array of tokens containing the numerator expression. The function assumes that the denominator divides evenly into all elements of the numerator. The function extracts the first element from the numerator expression. If it is a `+' or `-', the function recurses to divide each side of the expression by the denominator. If it is a `*', the function recurses to try to divide the left hand side of the expression by the denominator, and if it fails, it divides the right side of the expression. If the value is a `/', the function recurses to divide the numerator of the sub-expression by the passed denominator. If the value is a number, the function explicitly evaluates the expression. The function returns the array of divided expression tokens to its caller.
- dimPrint - This function converts a reduced dimension expression, consisting of an array of expression operators, values and variables in RPN (see dimEvaluate()), into C/C++ form, except for variable names, which are not expanded into source-code names at this stage. The variable name expansions are handled in the code-generation stage. The input to the function is the array of operator, values and variables, and the result string is placed in the variable $dimStrOut. The caller is responsible for clearing $dimStrOut prior to calling this function. This function de-queues the first element from the token array and compares it to known operators. If it is a `+', `-' or `/', the function writes the form `(left expression operator right expression)' to $dimStrOut, recursively calling dimPrint() to print the left and right side expressions. If the first element is a `*', the function checks the value of left and right side arguments, if either is `1', then it writes the other argument's value. If neither argument is `1', the function writes the form `(left expression * right expression)', recursing to expand the left and right expressions.
This section illustrates the structure of the command packet reader portion of the code-generator script, ipcl_reader.pl.
FIGURE 86. ipcl_reader.pl structure

- ipcl_reader main - This function initializes the global variables used by the ipcl_reader.pl Perl script. The function initializes the following configuration associative array parameters:
$cfg{inputbits} - Number of bits in command buffer word = 16
$cfg{inputname} - Variable name of command buffer "inputbuf"
- It also initializes the array of masks used by the reader code, $readerMasks[]. Each element of the array contains a right-justified number of `1's corresponding to the element's index in the array.
- readerGenerate - This function generates a C++ class for the passed command packet record definition. For input, it takes an optional parent class name, an optional basename to use for the generated classes, an optional record name of the packet header to prevent it from generating unnecessary access functions to the header (they're already inherited by parent's functions), an optional variable width, an optional variable offset, a inline member function flag, indicating whether or not to generate inline member functions, and a parsed record array. readerGenerate creates and emits a C++ class definition and member function implementations for the record defined in the parsed records array. The function forms the class name from the record name by replacing any spaces with underscores `_', and appending the result to the passed basename. It then appends the ".H" extension to the class name and creates the include file for the class using the formed name. It then writes a standard header to the include file, and include's its parent class's include file. The function then calls readerHeader() to write the class definition to the include file, and closes the file. The function then checks if inline functions were requested. If so, it re-opens the file for appending. If not, it creates the class's implementation file by appending the ".C" extension to the classname, writes a standard header to the file, and writes an include directive to the class's include file. The function then calls readerCode() to write the implementation to the open file (either the include file for inline's otherwise the new source file). Once the implementation has been written, the function closes the open file.
- readerHeader - This function writes the class definition for a command packet class. The inputs to the function include the parent class name, the command's class name, the record name of the packet header, and the parsed record array. The function first prints the class declaration:
class class_name : public parent name
{
public:
- It then iterates through each tokens in the parsed record array.
- If the token is the `record' keyword, the function increments a nested record count, extracts the record name and compares it with the passed header record name. If they match, the function sets a skip record counter. If not, the function prints a comment indicating that it is expanding a nested record definition.
- If the token is an `endrecord' keyword, the function decrements the nested record and skip record counters.
- If the token is a `fixed' keyword, the function increments an array flag counter.
- If the token is an `endfixed' keyword, the function decrements the array flag counter.
- If the token is a `variable' keyword, the function retrieves the field name of the variable length array, and saves the name until all of the tokens have been processed. It then increments the array flag counter.
- If the token is an `endvariable' keyword, the function decrements the array flag counter.
- If the token is a `field' keyword, the function retrieves the field name and sign. If the skip record counter is zero, the function calls readerSignature() to emit the member function access function declaration for the field. If the skip record counter is not zero, then an accessor function for the field is not produced. The function then checks and consumes the `endfield' keyword.
- Once all of the tokens have been processed, the function checks the variable length field name. If one was defined, the function emits the signature for a function which returns the number of elements in the variable length array:
unsigned get_CountOf_fieldname() const;
- The function then closes the class definition with a closing brace and semicolon.
- readerCode - This function implements the command packet accessor functions for each field of the command record. The inputs to the function include the parent class name, the command's class name, the record name of the packet header, whether or not to produce inline functions, and the parsed record array. The function iterates through each tokens in the parsed record array.
- If the token is the `record' keyword, the function increments a nested record count, extracts the record name and compares it with the passed header record name. If they match, the function sets a skip record counter. If not, the function prints a comment indicating that it is expanding a nested record definition.
- If the token is an `endrecord' keyword, the function decrements the nested record and skip record counters.
- If the token is a `fixed' keyword, the function increments an array flag counter, and sets local array offset, array width and array limit variables. The symbols within the array limit expression are converted into get_fieldname() functions. For example:
((#field_name# * 16) - 32)/14
((get_field_name() * 16) - 32)/14
- If the token is an `endfixed' keyword, the function decrements the array flag counter.
- If the token is a `variable' keyword, the function retrieves the field name of the variable length array, array offset, array width and array limit. It then increments the array flag counter. The array limit expression is converted as described above for the `fixed' keyword.
- If the token is an `endvariable' keyword, the function decrements the array flag counter.
- If the token is a `field' keyword, the function retrieves the field name, bit offset, bit width, sign, starting value and ending value. The function then checks and consumes the `endfield' keyword. If the skip record counter is zero, the function calls readerSignature() to emit the member function access function declaration for the field. It then calls readerField() to emit the implementation of the function. If the skip record counter is not zero, then an accessor function for the field is not produced.
- Once all of the tokens have been processed, the function checks the variable length field name. If one was defined, the function implements the function which returns the number of elements in the variable length array:
unsigned classname::get_CountOf_fieldname() const
{
return array limit expression;
};
- readerSignature - This function writes the signature of a field's accessor member function. The inputs to this function are the class name, the field name, the sign of the field, whether or not the field is contained within an array, whether or not the function is to be implemented as an inline function, and whether to emit the signature as part of a class declaration, or as part of the implementation of the function. The name of the generated accessor is "get_field_name." If the field is signed, the accessor returns an int result. If the field is unsigned, it returns an unsigned value. If the field is within an array, the generated accessor takes a unsigned index argument. If the signature is to be part of the implementation of the function, the class name is prepended to the accessor name (i.e. classname::get_field_name). For example, the signature for an unsigned array element within a class declaration is:
unsigned get_field_name(unsigned index) const;
- Whereas, at the start of its implementation, it looks like:
unsigned record_name::get_field_name (unsigned index) const
- readerField - This function implements the body of a field accessor. The inputs to the function are the name of the field, the bit-offset of the field, relative to the start of the record, the number of bits in the field, its sign, start value, end value, whether or not it is part of an array, and if so, the bit-offset to the start of the array, the number of bits in each array element, and the formula for the number of entries in the array. This function starts by writing an opening brace. If the field is in array, the function writes an assertion on the range of the input index. It then prints a comment indicating the position, and width of the field, and if it is within an array, the array element width. It then writes code which calls the inherited function, `getField()'. If the field is signed, it then emits code which sign-extends the result by a combination of shifts and type-casts. It then emits asserts which check the range of the value. Finally, the function writes code to return the value and writes the closing brace. For example, given a signed 3-bit field, starting at bit-position 5, whose range is from 1 to 5, and contained in an array of elements 17 bits wide, and containing at most 10 elements, the implementation might look as follows:
{
// ---- Range check index argument ----
assert (index < 10)
// ---- Offset = 5, Width = 3, Structure = 17----
unsigned out = getField (5, 3, 0x7, index, 17);
out = unsigned(int(out << 30) >> 30);
// ---- Value range checks ----
assert (out >= 1);
assert (out <= 5);
return int(out);
};
This section illustrates the structure of the telemetry packet writer portion of the code-generator script, ipcl_writer.pl.
FIGURE 87. ipcl_writer.pl structure
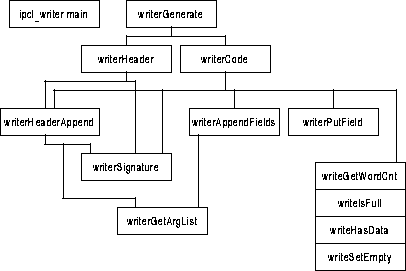
- ipcl_writer main - This function initializes the global variables used by the ipcl_writer.pl Perl script. The function initializes the following configuration associative array parameters:
$cfg{outputbits} - # of bits in word of the telemetry buffer = 32
$cfg{ouptputname} - Variable name of telemetry buffer "outputbuf"
$cfg{buflimit} - Max. words in telemetry buffer = 1024 * 32
- It also initializes the array of masks used by the writer code, $writeMasks[]. Each element of the array contains a right-justified number of `1's corresponding to the element's index in the array.
- writerGenerate - This function produces a C++ class which writes a record's fields into a telemetry packet buffer. For input, it takes an optional parent class name, an optional basename to use for the generated classes, an optional record name of the packet header to prevent it from generating unnecessary access functions to the header (they're already inherited by parent's functions), an optional variable width, an optional variable offset, a inline member function flag, indicating whether or not to generate inline member functions, and a parsed record array. writerGenerate creates and emits a C++ class definition and member function implementations for the record defined in the parsed records array. The function forms the class name from the record name by replacing any spaces with underscores `_', and appending the result to the passed basename. It then appends the ".H" extension to the class name and creates the include file for the class using the formed name. It then writes a standard header to the include file, and include's its parent class's include file. The function then calls writerHeader() to write the class definition to the include file, and closes the file. The function then checks if inline functions were requested. If so, it re-opens the file for appending. If not, it creates the class's implementation file by appending the ".C" extension to the classname, writes a standard header to the file, and writes an include directive to the class's include file. The function then calls writerCode() to write the implementation to the open file (either the include file for inline's otherwise the new source file). Once the implementation has been written, the function closes the open file.
- writerHeader - This function writes the class definition for the telemetry packet writer class. The inputs to the function include the parent class name, the telemetry packet's class name, the record name of the packet header, and the parsed record array. The function first prints the class declaration:
class class_name : public parent name
{
public:
- It then iterates through each tokens in the parsed record array.
- If the token is the `record' keyword, the function increments a nested record count, extracts the record name and compares it with the passed header record name. If they match, the function sets a skip record counter. If not, the function prints a comment indicating that it is expanding a nested record definition.
- If the token is an `endrecord' keyword, the function decrements the nested record and skip record counters.
- If the token is a `fixed' keyword, the function increments an array flag counter.
- If the token is an `endfixed' keyword, the function decrements the array flag counter.
- If the token is a `variable' keyword, the function retrieves the field name of the variable length array, and saves the name until all of the tokens have been processed. It then increments the array flag counter. The function then calls writerHeaderAppend() to form the signature for the access function which writes each element of the field and consumes all fields until an `endvariable' keyword is reached.
- If the token is an `endvariable' keyword, the function decrements the array flag counter.
- If the token is a `field' keyword, the function retrieves the field name and sign. If the skip record counter is zero, the function calls writerSignature() to emit the member function access function declaration for the field. If the skip record counter is not zero, then an accessor function for the field is not produced. The function then checks and consumes the `endfield' keyword.
- Once all of the tokens have been processed, the function emits the following signature:
unsigned getWordCount() const - Get number of words in packet buffer
- It then checks the variable length field name. If one was defined, the function emits the signatures for the following functions:
void setEmpty() - Set the number of appended items in the packet to 0
Boolean isFull() const - Determine if packet buffer is full
Boolean hasData() const - Determine if packet has any appended data
- The function then emits a protected instance variable, `unsigned _appended;', which holds the number of elements appended to the end of the telemetry packet buffer.
- The function then closes the class definition with a closing brace and semicolon.
- writerCode - This function implements the member functions of the telemetry packet writer class. The inputs to the function include the parent class name, the command's class name, the record name of the packet header, whether or not to produce inline functions, and the parsed record array. The function iterates through each tokens in the parsed record array.
- If the token is the `record' keyword, the function increments a nested record count, extracts the record name and compares it with the passed header record name. If they match, the function sets a skip record counter. If not, the function prints a comment indicating that it is expanding a nested record definition.
- If the token is an `endrecord' keyword, the function decrements the nested record and skip record counters.
- If the token is a `fixed' keyword, the function increments an array flag counter, and sets local array offset, array width and array limit variables.
- If the token is an `endfixed' keyword, the function decrements the array flag counter.
- If the token is a `variable' keyword, the function retrieves the field name of the variable length array, array offset, array width and array limit. It then increments the array flag counter. The function calls writerHeaderAppend() to print the declaration of the writer function for the array elements, and then writerAppendFields() to emit the function implementation, and consume the tokens up to the `endvariable' keyword.
- If the token is an `endvariable' keyword, the function decrements the array flag counter.
- If the token is a `field' keyword, the function retrieves the field name, bit offset, bit width, sign, starting value and ending value. The function then checks and consumes the `endfield' keyword. If the skip record counter is zero, the function calls writerSignature() to emit the member function access function declaration for the field. It then calls writerPutField() to emit the implementation of the function. If the skip record counter is not zero, then an accessor function for the field is not produced.
- Once all of the tokens have been processed, the function checks the variable length field name. If one was defined, the function calls writeGetWordCnt() to implement the function which returns the number of words in the telemetry packet buffer, writeSetEmpty() to emit the function which clears the `_appended' instance variable, writeIsFull() to implement the function which determines if the telemetry packet buffer is full, and writeHasData() to implement the function which determines if the telemetry packet buffer has data. If the packet is not variable length, then the function calls writeGetWordCnt() to implement the function which returns the static size of the telemetry packet.
- writerSignature - This function writes the signature of a field's accessor member function. The inputs to this function are the class name, the field name, whether or not the field is contained within an array, whether or not the function is to be implemented as an inline function, whether to emit the signature as part of a class declaration, or as part of the implementation of the function, and an array of function arguments. If the field does not define a variable length array, the name of the generated accessor is "put_field_name." If the field defines a variable length array, the name of the generated accessor is "append_field_name." If the field is within a fixed length array, this function inserts a unsigned index argument to the front of the signature's argument list. If the signature is to be part of the implementation of the function, the class name is prepended to the accessor name (i.e. classname::put/append_field_name). For example, the signature for an variable array element containing one subfield, within a class declaration is:
void append_field_name(unsigned index, unsigned subfield);
- Whereas, at the start of its implementation, it looks like:
void record_name::append_field_name (unsigned index, unsigned subfield)
- writerHeaderAppend - This function writes the signature for the accessor function for a field which defines a variable length array. The inputs to this function are the class name, the field name, whether or not the signature is part of the class definition, or part of the implementation, and the array of parsed record tokens. This function returns parsed record tokens after and including the `endvariable' keyword. The function calls writerGetArgList() form a $;-separated list of fields within the variable array element, and to consume all of the parsed record tokens up to the `endvariable' keyword. This function then splits the argument string into an array, and extracts the argument type and name, forming an array of argument statements. The function then calls writerSignature() to emit the signature for the append function. It then returns the reduced parsed record token array.
- writerPutField - This function implements an accessor function which writes a bit-field into the telemetry packet buffer. The inputs to the function include the class name, the field name, the bit-offset of the field, the number of bits in the field, whether or not the field is within a fixed-length array, and if so, the number of bits in one element of the array, the number of elements in the array. The start and end values for the field are also passed as input. This function writes the body of the access function, starting with the opening brace. If the field is part of an array, it writes an assert to check the passed index against the number of elements in the array. It then writes asserts to check the input value against the field's starting and ending limits. This function then writes a comment indicating the bit-position, width and, if applicable, array element width. The function then emits a call to the inherited function `putField().' Finally, the function emits a return statement, followed by a closing brace. For example, given a signed 3-bit field, starting at bit-position 5, whose range is from 1 to 5, and contained in an array of elements 17 bits wide, and containing 10 elements, the implementation might look as follows:
{
// ---- Range check index argument ----
assert (index < 10)
// ---- Value range checks ----
assert (input >= 1);
assert (input <= 5);
// ---- Offset = 5, Width = 3, Structure = 17----
putField (input, 5, 3, 0x7, index, 17);
return;
};
- writerAppendFields - This function implements an accessor function which appends the subfields from a variable length array element onto the end of the telemetry packet buffer. The inputs to the function include the class name, the field name defining the array, the bit-offset of the array, the number of bits within one element of the array, the maximum number of elements that the array can hold, and the parsed record array. The function returns the reduced parsed record token array. The function first calls writerGetArgList() to produce a string containing $;-separated list of field statements, and to consume the field tokens from the parsed record array. The function then starts writing the body of the function, starting with the opening brace. It then emits an assertion which checks if the telemetry buffer is full. The function then iterates through the argument list. For each argument, the function extracts the subfield's name, count if it is part of a subarray, bit offset, bit width, sign and range. It then iterates through the subarray's elements, emitting an assertion for the argument's value, and emitting a call to the inherited function `appendField().' Once all of the arguments have been processed, the function emits an operation to advance the `_appended' instance variable, and finally emits a return statement followed by a closing brace. For example, consider a field which defines variable length array of elements, whose subfields are `sub 1' and `sub2.' `sub 1' is 10-bits wide and starts 12-bits into the packet. `sub 2' is 4-bits wide, and starts 22-bits into the packet. Assume that no ranges were specified for the fields. The generated code may look as follows:
{
// ---- Range check index argument ----
assert (isFull() == BoolFalse);
// ---- sub 1 :: Offset = 12, Width = 10 ----
appendField (sub_1, 12, 10, 0x3ff, _appended, 26);
// ---- sub 2 :: Offset = 22, Width = 4 ----
appendField (sub_2, 4, 22, 0x0f, _appended, 26);
return;
};
- writerGetArgList - This function processes a field defining a variable length array. It extracts the series of subfields defined for the defining field. The input to the function is the array of parsed records. On output, the function returns a $;-delimited string of subfield specifiers, followed by the remaining array of parsed records. The format for the subfield specifiers consist of an argument specifier string followed by a set of field properties surrounded by angle brackets:
argument string<field count offset width sign srange erange>
- The function iterates through each of the parsed record tokens until it reaches an `endvariable' keyword.
- The function skips over `record' and `endrecord' delimited sections. When it encounters a `field' keyword, the function extracts the field name, offset, width, sign, and range. It then checks and removes the `endfield' keywords. The function then tests the field name. If the name consists of a basename followed by a 0, then it test subsequent fields to see if the fields can be combined into an array argument. If the subsequent field name consists of the same basename, followed by a 1, and its bit-width and sign match the first argument, the function iterates over subsequent fields until either the basename, the sequence number, bit-width or sign pattern are broken. If the subfield is not part of an array, the function emits an unsigned or int argument expression, followed by the field's properties. If the subfield is part of an array, it emits one argument expression for all of the participating fields, consisting of:
const unsigned or int basename[field count]
- Once all of the subfields have been processed, the function forms and returns the $;-delimited argument list string.
- writeGetWordCnt - This function emits an implementation of an accessor function which returns the number of words contained within a telemetry packet buffer. The inputs to the function are the class name, the width of one element of a variable length array, and the bit-position of the end of the fixed length portion of the packet. If no variable length array is present in the telemetry packet, the caller passes 0 for the array width. The function starts by writing the signature of the generated code. It then emits a comment indicating the position of the end of the fixed-length portion of the buffer, and the size of one element of the variable length array. If a variable length record is being processed, the function emits code to compute the number of words in the array based on the value of the `_appended' instance variable. If not, the function emits code to compute the length based on constants. For example, the generated code may look as follows:
unsigned class_name::getWordCount (void) const
{
// ---- Offset 10, Element Size 20 ----
unsigned wordcnt = 10 + (_appended * 20);
wordcnt = (wordcnt + 31) / 32;
return wordcnt;
};
- writeIsFull - This function emits code which determines whether or no the telemetry packet is full. This code is only emitted for variable length record definitions. The inputs to the function are the class name, the number of bits in one array element, and the bit-position to the start of the variable length array. The function emits code which computes the number of words in the array given one more element, and returns whether or not the result exceeds the limit for the packet. The function starts by emitting the function signature and opening brace. If the widths and offsets are evenly divisible by the number of bits in an output word, the function divides each element by the output bit-width. The function then emits code to compute the length of the packet, given 1 more element, and compares it to the limit supported by the packet buffer. For example, given an element of 10 and an offset of 11, the generated code may look as follows:
Boolean class_name::isFull (void) const
{
// ---- Offset 11, Element Size 10 ----
unsigned offset = 11 + ((_appended + 1) * 10);
return (offset > 4096) ? BoolTrue : BoolFalse;
};
- writeHasData - This function emits code which determines if a telemetry packet has had any data appended to it. This code is only emitted for records defining variable length telemetry packets. The input to this function is the class name. This function emits the following code:
Boolean class_name::hasData (void) const
{
return (_appended != 0) ? BoolTrue : BoolFalse;
};
- writeSetEmpty - This function emits code which zeros the counter which tracks the number of element appended to a telemetry packet buffer. This function is emitted only for variable length telemetry packets. The code emitted by this function is as follows:
void class_name::setEmpty (void)
{
_appended = 0;
};
Table of Contents
 Next Chapter
Next Chapter